「AIに分析させる」から「AIと分析する」~Looker Studioのレポートを対話前提の指示書に変えた話~

AIでのウェブサイト分析ってAIに丸投げして答えが出てくるイメージですよね。
ここに関しての自分の違和感と解決方法を丸山さんに話したら興味を持ってくれたのでまとめてみました。
※丸山さんの記事はこちら
AI分析について話していたら”新しい何か”が生まれた
便利なんだけど何かが引っかかっていた
GA4の分析をAIにやってもらう方法は、いまや珍しくないですよね。
MCPサーバーでGA4に直接つなぐ、あるいはLooker StudioのPDFをアップしてプロンプトで「分析して」と投げる。どちらも速いし、それなりの結果が返ってきます。
ただ、使っているうちに3つの引っかかりが出てきました。とくに「プロンプト一発」と「MCP接続」のやり方に対してです。
- AIが出してきたものを鵜呑みにしがち:それっぽい所見が一気に出てくるので、つい鵜呑みにしてしまう。
- 背景情報が伝わらないからAIが誤解する:データには映らない事情を知らないまま、AIは平気で断定してくる。
- これだと「人間不要」になってしまう:突き詰めると「人を抜く」方向の設計に見える。
3つ目が自分にとっては一番大きい引っかかりでした。分析の価値ってデータを読むことより、データに映らない事情や知っていることから数字を見ることにあるはずです。そこを抜いてしまったら、出てくるのは「もっともらしいが文脈を外した分析」になると思ってます。
AIにGA4の分析をさせてみてしっくりこない原因はこれかなと。
ウェブサイトをAIで分析する3つのやり方
AIで分析するやり方は大きく3つに分けられます。
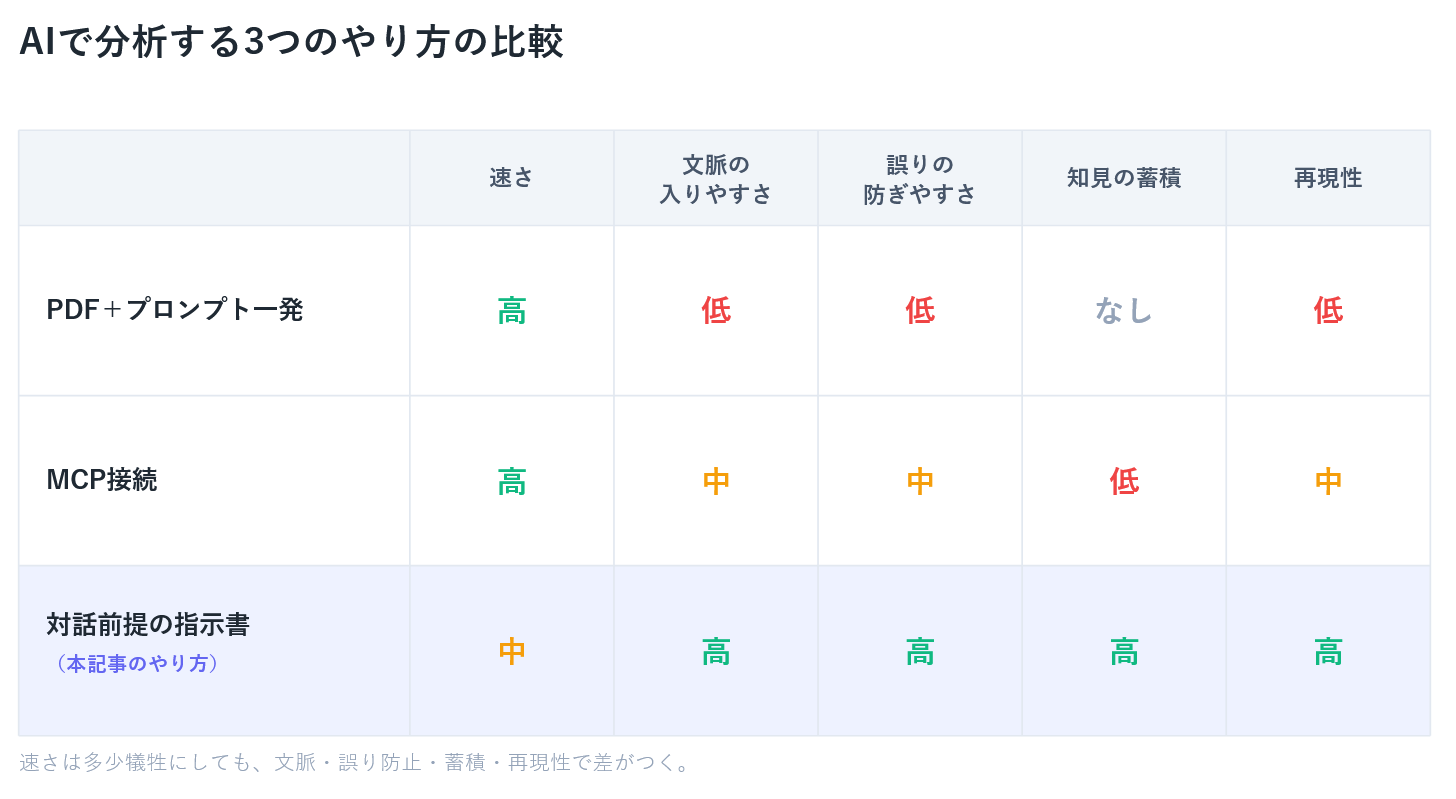
- PDF+プロンプト一発:手軽で速い。ただしモデルが空白を推測で埋める/修正ループがない/知見が蓄積しない/自信満々の誤りがそのまま成果物になる。
- MCP接続:リアルタイム取得や自動化に向く。ただし一問一答に流れやすく、成果物の形や文脈の入れ方は場当たり的になりがち。
- 対話前提の指示書(自分のやり方):手数はかかる。代わりに文脈が入り、人間が確定のゲートになり、毎回同じ規格の成果物が出る。
PDFとMCPは「自動化」寄りです。
多くのサイトを分析するとか毎月作業をするとかルーチンワークには向いていると思います。モニタリングとか定点観測ですね。ただ、これだと「このレポート意味あるの?」ってなりがち。何らかの解釈とか考察を入れて、アクションにつなげないといけないのが難しい。
自分のやり方は「対話」。
何度もやり取りして、こちらの事情などを知ってもらってまとめてもらう。AIは優秀なまとめ人という感じ。
やったのはLooker StudioのレポートへのコメントをAIでドキュメント化
特別なことをしたわけではありません。
自分がLooker Studioで作っていた月次レポートでやっていることを、AIと一緒にできるようにしただけです。
- レポートを1枚ずつ見ながら、「自分はこのページで何を見て、どう判断しているか」をコメントしていった。
- そのコメントをAIにドキュメント化してもらった。頭の中の暗黙知を言語化してもらう作業ですね。
- それを対話を含んだAI用の指示書に変換した。「データ取得 → 所見の草案 → 担当者へ質問 → 確定」という流れを、手順として指示書に埋め込んだ。
- 指示書をジャンルごと(ユーザー属性/テクノロジー/集客/エンゲージメント/維持率)に分割した。
こんなデータがあったら考えられることがこれだけあって、それぞれについてどう判断していくかをちまちまとまとめていきました。いくつかのサイトで数か月やっていくとある程度は出そろいました。
また、指示書をジャンルごとに分けておくと、アップデートがとにかく楽。「今回こういう気づきがあった」というのが出たら、そのジャンルの判断基準に1行足すだけで済みます。指示書がどんどん育っていく感覚です。
この方法の特徴は「AIに分析させる」のではなく「AIと分析する」
AIの出力を結論ではなく仮説というかデータからわかることとして扱い、人間はその報告を受けて対話するイメージです。一通りのデータを見て現象をまとめるのって時間がかかるのでそこはAIにお任せ、その先に人間が集中するという流れ。
※基本の考えはこの記事と同じです。
AI活用に完全に乗り遅れていると焦っていたけど、自分のやり方に合わせてAIを使っていたんだと気づいた
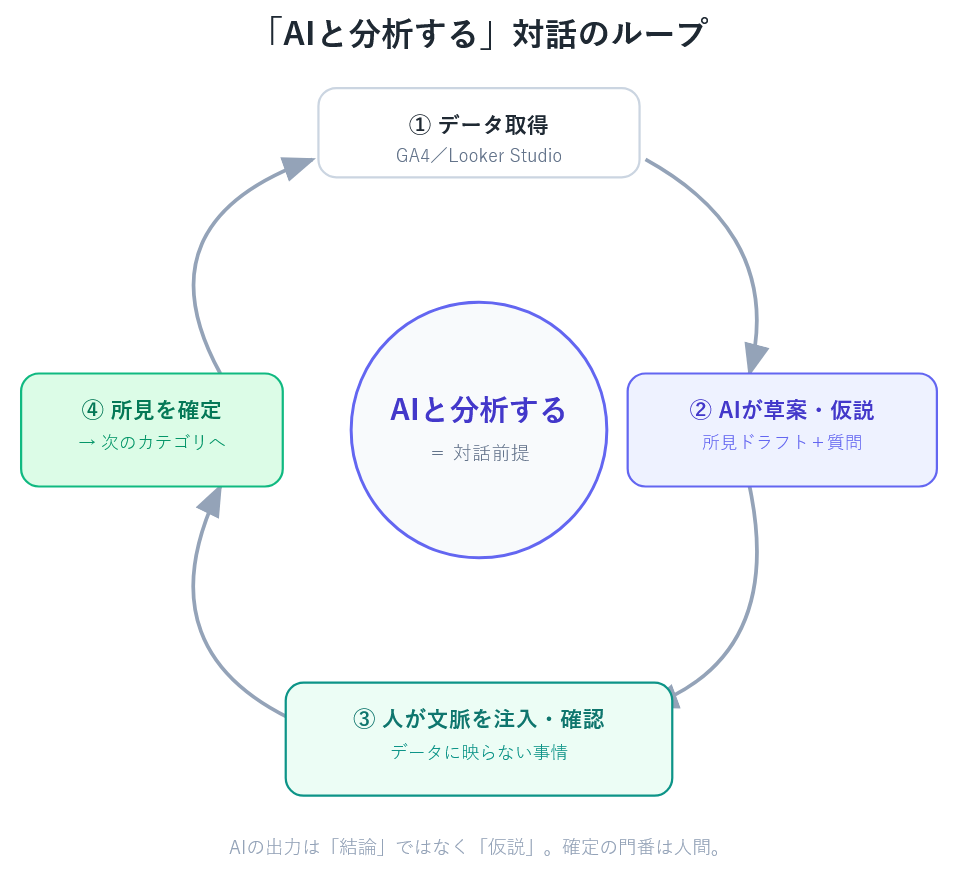
この方法の良いところはデータに映らない文脈を区切りごとに注入できる点です。
例えばこんなとき。
- スマホはIPから正確な位置が取れず、地域が東京・大阪に寄って記録される
- あるページはハブなので、そのページ自体のCVはゼロでも問題ない(CVは別ページで計上される)
- ある流入が伸びたのは、オフラインのリアルイベントが裏にあったから
こうした事情を知らないまま分析すると、AIは「圏外流入が異常」「このページは機能していない」と、もっともらしく誤読します。対話前提は、その典型的な誤読を構造的に防ぐ仕組みです。
副次的な効果も大きいです。
- 手順書=方法のドキュメント化:判断基準・質問テンプレ・出力フォーマットまで外に出してあるので、属人性が下がり、人が変わってもモデルが変わっても再現できる。プロンプト力ではなく手順に知見が乗っかります。
- 気づき → 指示書更新のループ:繰り返すたびに判断基準が増え、精度が上がっていく。一発型は何回やっても学習しませんが、これは資産が積み上がる。
- 出力の規格化(✅⚠️🚨・サマリー表・要確認事項):月次で比較しやすく、そのまま提出物にできる。
- 「分からないことは”要確認・後回し”として残す」:無理に結論を出させないので、異常値の深追いで迷宮入りしない。
実例:「東京・大阪が多い」をどう解釈したか
先ほど触れた「スマホはIPから正確な位置が取れない」という話を、実際のやり取りで見てみます。中部地方のある地域密着型の住宅メーカーのサイトで、ユーザー属性を分析したときのものです(数値は丸め、固有名は伏せています)。
① AIが出してきた草案(けっこう饒舌)
まず、AIはこんなサマリー表を出してきます。
| 項目 | 内容 | ステータス | コメント |
| アクセス元(国) | 日本 約96% | ✅ 正常 | 海外はごく少量。クローラー的だが許容範囲 |
| 地域(都道府県) | 中心県 約40%・東京 約10%・大阪 約10% | ⚠️ 要確認 | 中心県はサービスエリアと整合。東京・大阪はサービスエリア外で、広告のターゲティングが広すぎる可能性 |
| 年齢構成 | 判別層は25〜44歳が中心 | ✅ 正常 | 子育て・一次取得層と一致 |
| 性別構成 | 判別層はほぼ均衡(CVはやや男性寄り) | ✅ 正常 | 推定値のため参考値 |
| 言語 | 日本語 約94%・英語 約5% | ⚠️ 要注意(軽微) | 英語はボット的・非CV。経過観察 |
さらに所見として続けます。
「地域分布で気になるのは、サービスエリア外である東京・大阪が上位に入っている点です。CVも東京・大阪から一定数発生しており、サービスエリア外のユーザーに広告が配信されている=ターゲティングを見直す余地があるかもしれません。 仮説:このサイトはモバイル比率が約9割と高いため、東京・大阪の上位表示はスマホのIP測位の影響という可能性もあります。実際のところ、東京・大阪の流入は獲得したいターゲットでしょうか? 他に心当たりはありますか?」
と、表だけでなく仮説や追加の質問までかなりの分量で返してきます。
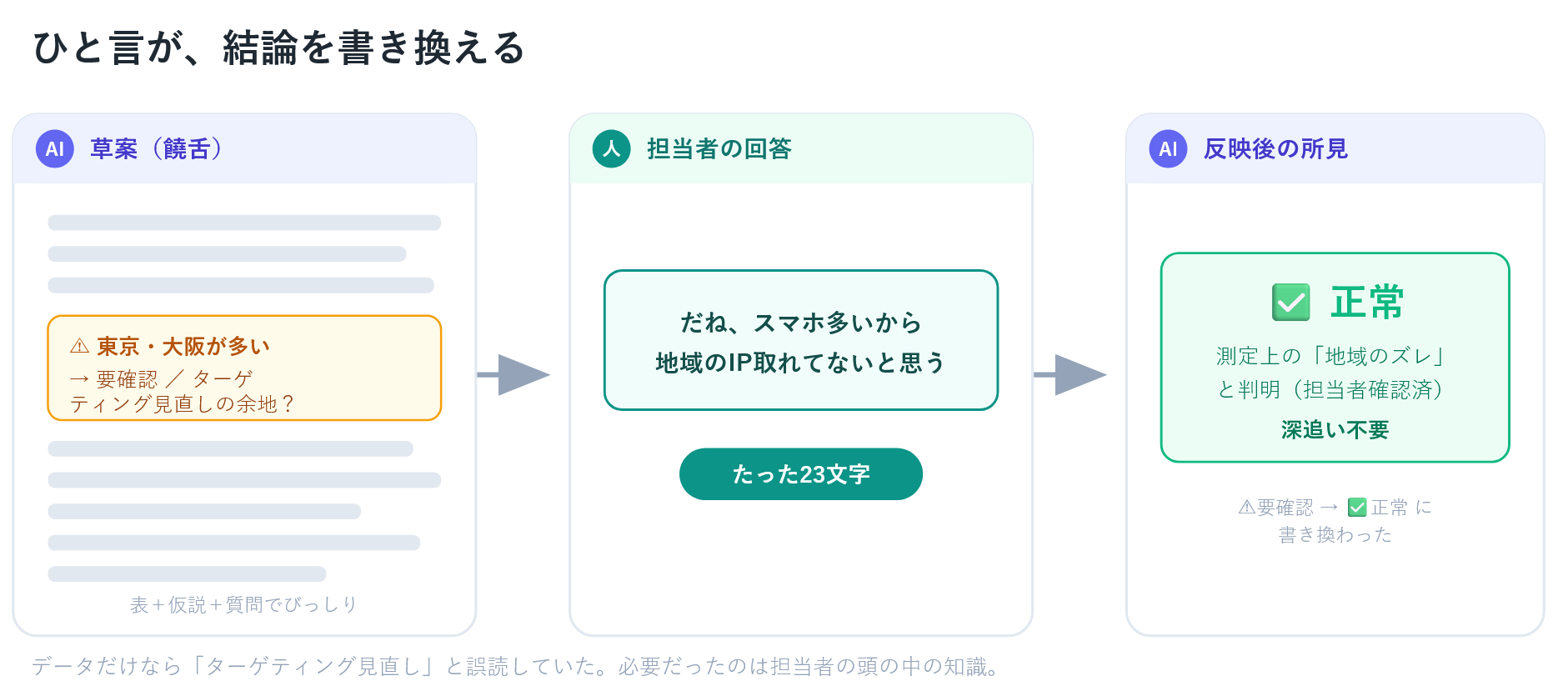
② 担当者(人間)の回答
だね、スマホ多いから地域のIP取れてないと思う。
これだけ。たった一行、23文字です。
AIがあれだけ並べた「要確認」「ターゲティング見直しの余地」を、この一言がまるごと書き換えました。
③ 反映後の所見
地域:✅ 正常。中心エリアの県が利用・CVともに上位でサービスエリアと整合。東京・大阪の上位は、スマホで位置情報が正確に取れず、通信キャリアの接続ポイントが集中する東京・大阪として記録されることによる”地域のズレ”(担当者確認済み)。実態としてのサービスエリア外流入ではないため、深追いは不要。
もしAIに「分析して」と一発で投げていたら、出力はおそらく「サービスエリア外の東京・大阪からの流入が多く、ターゲティングの見直しが必要」になっていたはずです。データだけを見れば、そう読むのが自然だからです。
実際には測定上の見え方の問題であって、施策の課題ではありませんでした。その判断に必要だったのは、データの中ではなく、担当者の頭の中にあった「スマホはIPがズレる」という知識です。AIが仮説を出し、人間がひと言で文脈を埋め、誤った結論を未然に防ぐ。対話前提のやり方が一番効くのは、まさにこういう場面です。
速さと引き換えになっちゃいますが
もちろん弱点もあります。
- 手数とやり取りの回数がかかる(速くはない)
- 自分が文脈を持って関与しないと価値が落ちる
- 型に乗らない突発的な事象は拾いにくい
- そもそも完全自動化を目指していない
速さを少し犠牲にして、正確さと、続けられる仕組みと、提出できる品質を取りにいく設計だと思っています。
このやり方が向く人・向かない人
ここまで読んで気づいた方もいると思いますが、この方法は誰がやっても同じ結果になるわけではありません。使う人によって効き目が大きく変わります。
向いているのは:
- これまで自分の手で分析をやってきた人
- 業界やクライアントの背景情報を多く持っている人
- 現場(営業・店舗・イベント・クライアントとの会話)とつながっていて、データの裏側を知っている人
こういう人は、AIが出した草案に対して「いや、これはスマホのIPだよ」「このページはハブだからCV0で正常」と、すぐに文脈を返せます。先ほどの23文字のように、その一言が分析の質を決めます。
向いていないのは:
- 分析経験が浅く、AIの出力が正しいか判断できない人
- 現場と話せておらず、データの裏側の事情を持っていない人
この場合、AIが出した「もっともらしい誤読」を見抜けずに、そのまま通してしまう危険があります。冒頭で書いた「鵜呑みにしがち」が、いちばん起きやすいパターンです。文脈を補える人がいないと、対話前提のうまみは出ません。経験を積んでいる途中なら、まずは現場を知ること・自分で一度データと格闘することが先で、それからこの仕組みに乗せると効いてきます。
まとめ:自動化ではなく拡張
これは自動化じゃなくて拡張だと思ってます。人を抜く仕組みじゃなくて、人の判断を載せる仕組みですね。
AIが賢くなるほど任せきりにしたくなるけど、データに映らない文脈と、それをどう読むかは、いまのところ人にしかない。むしろAIが「読む」を肩代わりしてくれる時代だからこそ、差がつくのは現場で見て聞いて感じたことのほうです。一次情報と経験はAIがどれだけ賢くなっても自動では手に入らないんですよね。
AIで浮いた時間を、また別の効率化に回すんじゃなくて、現場に行くとか人と話すとか、アナログにつぎ込むのがいいと思ってます。たぶんそこでいいことが起きる。
おまけ:今回の話もちょっと入ったセミナーです!
- Google Search Console、GA4、Clarityで簡単な分析
- ページ改善をAIと一緒に
といった内容を40分でコンパクトにお話します。

お申し込みはこちらから!
皆様のご参加をお待ちしております~!